



- 原文標題:《「我不需要更好的模型了」:Reddit 熱帖下的AI 眾生相》
- 原文作者:星期五,深潮TechFlow
Anthropic 剛剛交出了一份紙面上無可挑剔的成績單。
6 月9 日發布的Claude Fable 5 是該公司首個面向公眾開放的Mythos 級模型,在真實軟體工程任務基準SWE-Bench Pro 上拿下80.3%,領先自家上一代旗艦Opus 4.8 約11 個百分點,領先GPT-5.5 超過20 個百分點。
但用戶的反應潑了一盆冷水。
發布三天后,r/artificial 版塊(週訪問量30.5 萬)的一篇熱帖標題寫道:「Claude Fable 讓我意識到,我不需要更好的模型了。」
發文者Axi0m-22 說,他用Fable 跑了一段時間安全研究和日常工作,然後幾乎立刻切回了Opus 寫代碼、Haiku 處理雜活。他打了個比方:這就像拿著iPhone 14 看iPhone 17 發布,「你知道新的更好,但你想的是:算了,我這個挺好。」
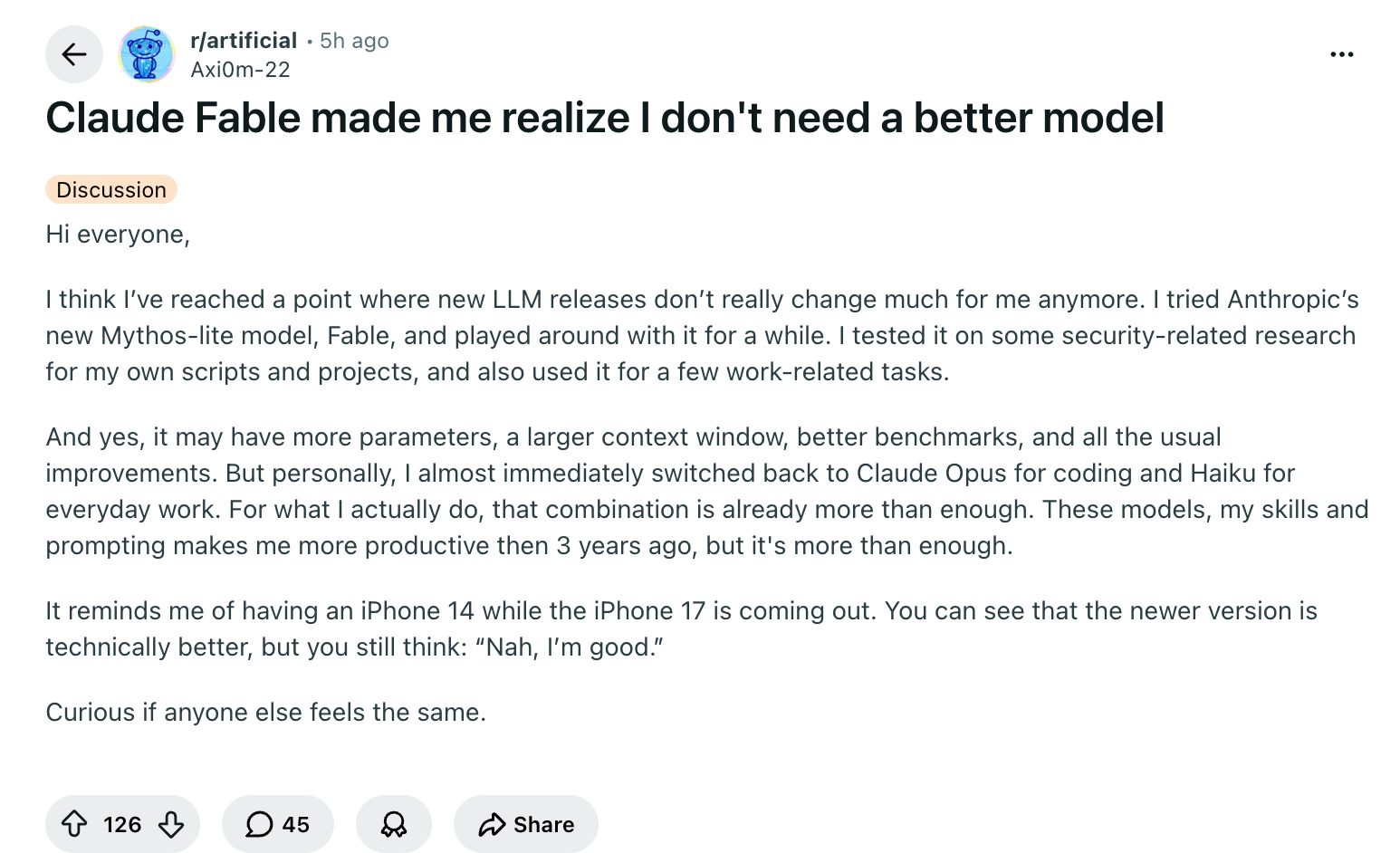
高讚區被「夠用派」佔領:模式美感疲勞成主流情緒
排名第一的評論獲得42 個讚:「除了更大的上下文窗口,我從Opus 4.5 開始就不再覺得需要更強的模型了。」
另一位用戶hyprlab 的表態拿到13 個讚:「換一個燒token 更狠的模型,我看不到對我工作流程的好處,Opus 4.8 高強度模式已經足夠舒服。」
這類發言背後有一個共同的成本帳本。
Fable 5 的API 定價為每百萬輸入token 10 美元,接近Opus 4.8 的兩倍。用戶siromega37 說得直白:「token 消耗更高,但沒有投資回報。我覺得我們正在看到平台期,泡沫終將被刺破。」
用戶hobopwnzor 給出了更系統化的解讀:「我們已經在S 型曲線的頂部待了一陣子。近期的進步主要來自工具調用和外圍工程,不是模型本身的能力。」
安全護欄成最大槽點:「90% 的用途直接被拒絕」
如果說「夠用」還只是情緒,那麼對安全護欄的抱怨就是具體的產品問題了。
根據Anthropic 官方說明,Fable 5 與僅向少數機構開放的Mythos 5 共享同一底層模型,區別在於Fable 加裝了安全分類器:涉及網路安全等高風險領域的請求會被攔截,轉由Opus 4.8 代答。官方稱這套機制調校得偏保守,平均在不到5% 的會話中觸發,且會誤傷無害請求。
在這篇Reddit 貼文下,觸發率的體感顯然遠高於5%。獲得17 個讚的用戶jradoff 說,他讓Fable 檢查自己代碼的安全性,結果「只要提到安全相關的事,它基本上都拒絕處理」,然後被回退到Opus。另一條12 讚的評論更不客氣:「你想用它幹的事90% 都會被拒,等於沒用。」
付費用戶的怨氣更重。訂閱200 美元檔位的用戶kaitava 寫道:「我付著雙倍的用量費,想讓它做一次安全審查,結果被降級到Opus。這下我對它的一切都不喜歡了,就等OpenAI 追上來。」
對於一款主打能力躍遷的旗艦產品,「為安全付出的可用性代價」正成為用戶決定是否買單的核心變數。
反方聲音:重度任務使用者的體感是「夜與晝」
熱帖之下並非沒有反對者,反方的畫像相當清晰:任務越重,評價越高。
使用者Phylaras 的評論拿到15 個讚:「Fable 對我產生了實質區別。那些對上下文視窗要求巨大的複雜任務,它抓出了之前沒被發現的錯誤。」一位自稱在做高能物理仿真的用戶表示,單一仿真模型動輒8000 到1 萬行程式碼、上百個模型,「有個能獨立工作、太期待環境
最激烈的反駁來自用戶Navetz:「說實話,用過這個模型的人會覺得這種帖子是瘋話。對我來說它聰明得判若兩人,我一直在不停地用。我跟非技術朋友解釋:這相當於從大學生球員直接換成NBA 首發。」
也有人給了折衷的用法。使用者ready-eddy 建議把Fable 當「規劃者和修復者」,而不是日常的「建造者」,除非不在乎燒錢。另一則評論總結得更像使用手冊:用Fable 算表格是選錯了模型,用Haiku 跑16 個智能體的複雜任務同樣是選錯了模型,「不存在天生的壞模型,只有用錯場景的模型」。
跑分與體感脫鉤之後,公開AI 還會更強嗎
這場爭論裡最有趣的一則評論,把話題從產品引向了產業結構。
用戶KedMcJenna 提出了一個「公開AI 凍結論」:普通人能摸到的模型可能會永遠停在當前水平附近,而企業和政府精英將持續獲得更強的私有模型,「我們知道的至少有Mythos,很可能還有更強的、我們永遠不會聽說的模型」。
這條評論指向一個事實:Mythos 5 確實不對公眾開放,目前僅透過Project Glasswing 計畫提供給網路防禦機構和關鍵基礎設施企業。
把跑分和輿情放在一起看,結論不矛盾。
基準測試衡量的是能力上限,而Reddit 高讚區反映的是日常需求的天花板。當大多數使用者的任務在Opus 4.6 時代就已被滿足,更強的模型只能在物理模擬、超長上下文這類極端場景中證明自己。模型廠商面對的不再是「做不做得到」的問題,而是「誰需要、願意付多少錢、能容忍多少安全摩擦」的問題。
發售三天,Fable 5 在跑分榜和輿論場拿到了兩份完全不同的成績單。哪一份比較接近真相,要看Anthropic 接下來調整安全分類器的速度,以及重度使用者的錢包投票。














