



在人工智慧基準測試中,自從GPT-3發布以來,OpenAI 的 ChatGPT 一直是生成式人工智慧(AI)模型領域的標竿。它的最新模型 GPT-4o 和其主要競爭對手 Anthropic 的 Claude-3,在過去一年左右的大多數基準測試中一直處於領先地位。然而,最近該領域卻出現了一個新的黑馬,悄悄地打敗了 GPT-4o 與 Claude-3。
上週,Google 秘密發布的最新 AI 模型實驗版本 Gemini 1.5 Pro 在「LMSYS 語言模型競技場」中進行了測試,最終以 1300 分超越 GPT-4o 與 Claude-3.5,首次奪得第一名。需要強調的是,儘管測試結果表明它總體上比其他競爭者更有能力,但基準測試並不一定能準確反映 AI 模型的能力和限制。
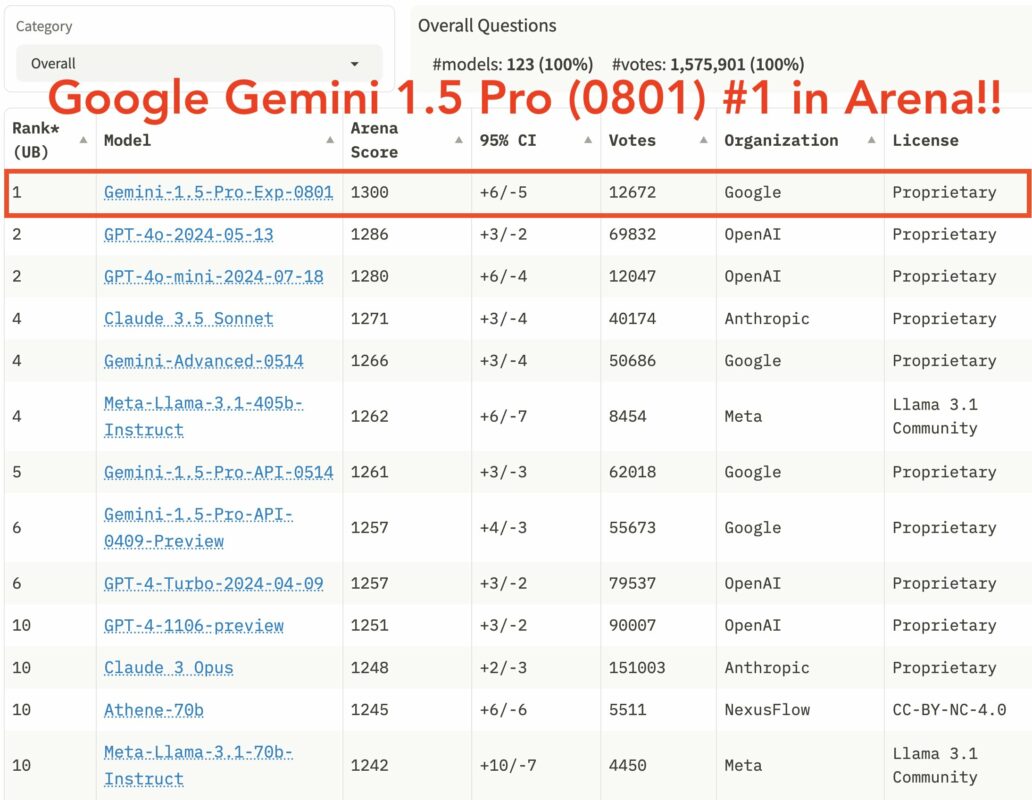
這一測試結果很快就在社群媒體的 AI 社群中引發廣泛關注。有用戶在社群媒體上對 Gemini 的最新版本讚不絕口,甚至有 Reddit 用戶稱它「將 GPT-4o 遠遠拋在了身後」。目前尚不清楚 Gemini 1.5 Pro 的實驗版本是否將成為未來的標準版本。雖然截至本文發佈時它仍然可用,但由於目前仍處於早期發布或測試階段,因此該模型可能因安全或適應性原因被撤銷或更改。
















